
The Five States of Data: Optimizing Automated Decisioning Systems
In the modern enterprise landscape, data is no longer a static asset confined to passive dashboards; it is a dynamic flow that informs every aspect of institutional intelligence. To build robust automated decisioning systems, organizations must move beyond simple data collection and master the Five States of Data. Understanding these states—historical, external, behavioral, real-time, and simulated—is essential for transforming raw information into predictive power and operational agility.
What are the Five States of Data?
The Five States of Data represent a comprehensive framework for categorizing information based on its source, velocity, and predictive utility. Rather than viewing data as a monolithic repository, this framework treats data as a shifting spectrum of signals. Each state serves a specific purpose in the decision-making pipeline, from establishing baseline probabilities to enabling instantaneous, event-driven responses. By classifying data into these five distinct categories, enterprises can better align their technology stacks with their strategic business objectives.
“Internal data is competitive differentiation and it is earned; the information no one else can see is often what matters most in decision intelligence.”
The Strategic Value of Modern Data Orchestration
The strategic value of managing these data states lies in the ability to move from reactive reporting to proactive anticipation. Organizations that successfully orchestrate these states can evaluate risk exposure, capital allocation efficiency, and customer stability in real time. This orchestration creates an “enterprise nervous system” capable of sensing market shifts and adjusting automated responses without manual intervention. Building on this, the integration of diverse data states reduces institutional blind spots, ensuring that decisions are not just fast, but contextually accurate.
Core Elements of the Five States of Data
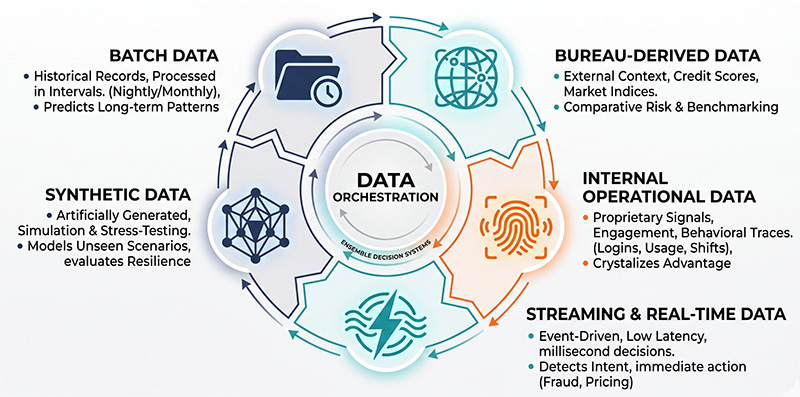
To implement high-performance automated decisioning systems, practitioners must understand the unique characteristics of each state:
- Batch Data (The Foundation): Processed at defined intervals (nightly or monthly), this represents institutional memory. It includes financial statements and transaction histories, serving as the primary training ground for predictive models to identify long-term patterns like seasonality and churn.
- Bureau-Derived Data (The External Lens): Sourced from third-party providers, this state provides ecosystem context. It includes credit scores and market indices, allowing firms to compare internal customer behavior against broader market trends.
- Internal Operational Data (The Competitive Core): These are proprietary, high-depth signals generated by direct customer interactions, such as digital clickstreams or service friction. This state often surfaces the earliest indicators of behavioral change.
- Streaming and Real-Time Data (The Action Layer): Low-latency, event-driven data that represents what is happening in the current millisecond. This state is critical for intent detection, fraud prevention, and dynamic pricing.
- Synthetic Data (The Emerging Dimension): Artificially generated data used to simulate scenarios that have not yet occurred. This allows enterprises to stress-test systems against economic shocks or rare operational disruptions without risking real capital.
“By 2025, 70% of organizations will shift their focus from big to small and wide data, providing more context for analytics and making AI less data-hungry.”
— Gartner Research
Real-World Applications
In practice, a modern lending institution utilizes the Five States of Data to make sophisticated credit decisions. The system analyzes historical repayment patterns (Batch), incorporates an external credit score (Bureau), monitors recent shifts in payment timing (Internal Operational), and evaluates the attributes of the current application session (Streaming). Finally, the institution uses Synthetic Data to ensure the resulting loan portfolio can withstand a hypothetical 3% rise in interest rates. This layered approach ensures the decision is informed by history, context, behavior, and future possibility.
Implementation Best Practices
Successful implementation of these data states requires a focus on the feedback loop. Automated systems should not be treated as one-way pipelines; every decision made must generate new data that flows back into the system. For instance, a declined transaction should become a data point that refines future fraud detection thresholds. Furthermore, practitioners should prioritize data governance and continuous monitoring to prevent predictive decay as market conditions evolve. In practice, the goal is to create a self-correcting engine where real-time outcomes constantly recalibrate long-term strategic models.
Key Takeaways
- Orchestration Over Isolation: The power of decisioning systems comes from the interplay of all five states, not any single data source.
- Competitive Edge: Proprietary internal operational data is the primary driver of differentiation in a commoditized market.
- Future-Proofing: Synthetic data is essential for preparing models for “black swan” events and unseen economic conditions.
- Continuous Learning: A robust feedback loop ensures that automated decisions remain accurate and relevant over time.


